
Parsing FreeMind files
This is a bit of an addendum on my previous post. - I wanted to convert some FreeMind mind-maps into other formats. FreeMind is pretty cool, especially as it’s file format is fairly straightforward XML, so lots of other mind mapping programs, like XMind, will read and write FreeMind files.
Initially what I wanted was to get the data into a spreadsheet. I had a map vaguely like:
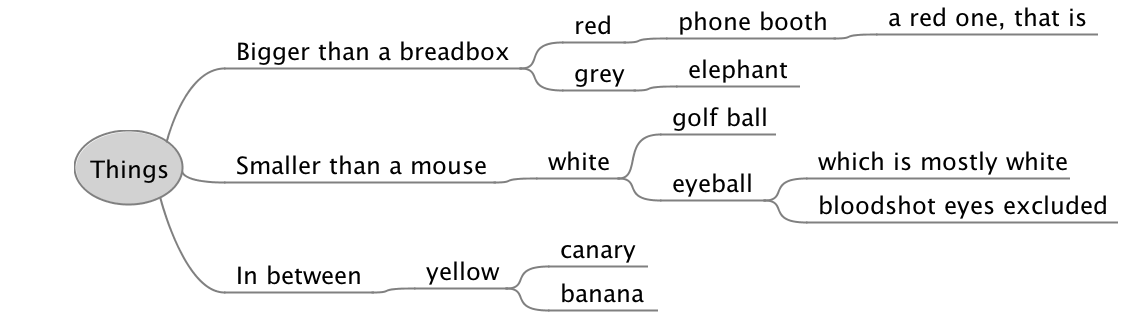
And I wanted to turn this into tabular data in a spreadsheet:
| Bigger than a breadbox | red | phone booth |
| Bigger than a breadbox | grey | elephant |
| Smaller than a mouse | white | gold ball |
| Smaller than a mouse | white | eyeball |
| In between | yellow | canary |
| In between | yellow | banana |
You get the idea - I didn’t want every node, just those at level 3, and I needed to denormalise them back into columns.
Now, there are lots of freemind examples to manipulate maps - using xslt. Yuck. This stuff is so easy in clojure.
I’ll do this at the repl, for simplicity. First, some namespaces:
(ns fm-parse.blog
(:require [clojure.data.xml :refer [parse-str]]
[clojure.zip :refer [xml-zip up down left right]]
[clojure.data.zip :as c-d-zip]
[clojure.data.zip.xml
:refer [xml-> xml1-> attr attr= text]]
[clojure.java.io :as io]
[clojure.data.csv :refer [write-csv]]))
It’s a pity the xml stuff is spread over so many namespaces, but that’s somewhat the clojure way - libraries are built up as incremental changes to existing libraries.
(Normally I’d add more :as namespace aliases, but I wanted to keep the code terse so it’s more readable on small devices)
Next, read the freemind xml into memory:
(def xml-data (parse-str (slurp "things.mm")))
(clojure.pprint/pprint xml-data)
{:tag :map,
:attrs {:version "1.0.1"},
:content
({:tag :node,
:attrs
{:CREATED "1396204283978",
:ID "ID_1617316526",
:MODIFIED "1396204290625",
:TEXT "Things"},
:content
({:tag :node,
:attrs
{:CREATED "1396204291304",
:ID "ID_1543131992",
:MODIFIED "1396204295075",
:POSITION "right",
:TEXT "Bigger than a breadbox"},
...
; define the root of what we care about:
(def root (-> xml-data :content first))
The nodes we want have :TEXT attributes with the name of the node, and children with child notes. That’s most of what we care about. I’ll define a function to get the node name from a zipper location:
(defn zip->txt [n] (attr n :TEXT))
Then for example, we can get the text from the phone booth node:
(def phone-booth (xml1-> (xml-zip root) down down down))
=> (var fm-parse.blog/phone-booth)
(zip->txt phone-booth)
=> "phone booth"
What we want for the spreadsheet is a list (really a seq) of all the nodes from the root down to a leaf. There’s an “ancestors” function in the zip code that will do what we want - I’ll build it up step by step:
(map zip->txt (ancestors phone-booth))
=> ("phone booth" "red" "Bigger than a breadbox" "Things")
(reverse (map zip->txt (ancestors phone-booth)))
=> ("Things" "Bigger than a breadbox" "red" "phone booth")
(rest (reverse (map zip->txt (ancestors phone-booth))))
=> ("Bigger than a breadbox" "red" "phone booth")
make this a function:
(defn as-text-seq [zloc]
(->> (c-d-zip/ancestors zloc)
(map zip->txt)
reverse
rest))
=> (var fm-parse.blog/as-text-seq)
(as-text-seq phone-booth)
=> ("Bigger than a breadbox" "red" "phone booth")
That’s the first line of our spreadsheet! The clojure.data.csv library takes sequences like this trivially - I’ll show this below - but we want to find all the right nodes to export.
If you look at the mind map above, what we want is all nodes exactly 3 levels deep in the tree. We can codify that as a match for the xml-> function:
(xml-> (xml-zip root) :node :node :node (attr :TEXT))
=> ("phone booth" "elephant" "golf ball" "eyeball" "canary" "banana")
Those are the leaf nodes - now just call as-text-seq on each of them:
(def level3-nodes (xml-> (xml-zip root) :node :node :node))
(def csv-data (for [leaf level3-nodes]
(as-text-seq leaf)))
csv-lev3
=> (("Bigger than a breadbox" "red" "phone booth") ("Bigger than a breadbox" "grey" "elephant") ("Smaller than a mouse" "white" "golf ball") ("Smaller than a mouse" "white" "eyeball") ("In between" "yellow" "canary") ("In between" "yellow" "banana"))
(with-open [out-file (io/writer "sample.csv")]
(write-csv out-file csv-data))
And we’re done - you can import this csv file into Excel or LibreOffice or whatever you use.
Note, you can use a simple extension of this to write the freemind file to a GraphViz dot file very easily - I do this to import mindmap data into OmniGraffle. I’ll leave this as an exercise for the reader!